Von Neumann and Harvard architectures are two fundamental computer architecture designs that have been influential in shaping the way computers process and store data. As computing technologies continue to advance, understanding the differences between these two architectures becomes crucial for engineers, developers and technology enthusiasts alike.
Let us talk about Von Neumann and Harvard architectures in the context of their characteristics, advantages and real-world applications.

The Von Neumann architecture
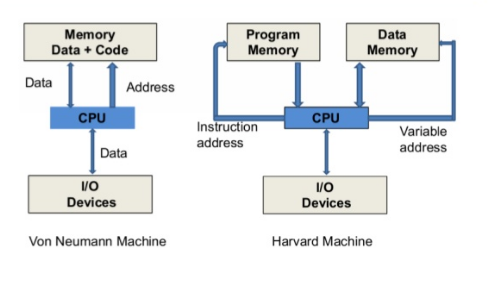
The Von Neumann architecture also known as the Von Neumann model or Princeton architecture is a theoretical computer design based on the concept of stored-program where programs and data are stored in the same memory. The concept was designed by a mathematician John Von Neumann in 1945 and currently serves as the foundation of almost all modern computers.
Neumann machine consists of a central processor with an arithmetic/logic unit and a control unit, a memory, mass storage and input and output. The architecture is characterized by its integration of data and instructions within the same memory and its sequential execution of instructions.
Key Features of the Von Neumann architecture
- Stored-Program Concept: The Von Neumann architecture introduced the revolutionary idea of a “stored program.” In this concept, both the instructions that control the computer’s operations and the data it processes are stored in the same memory system. This allows programs to be easily modified and manipulated, and it enables a high degree of flexibility in computer operations.
- Single Memory System: In the Von Neumann architecture, a single memory system stores both program instructions and data. This memory is accessible by the central processing unit (CPU) for both reading and writing. The CPU fetches instructions from memory and executes them sequentially.
- Sequential Execution: Instructions are processed and executed one at a time in the order in which they appear in memory. The control unit of the CPU fetches an instruction from memory, decodes it to determine the operation to be performed, executes the operation, and then advances to the next instruction.
- Arithmetic Logic Unit (ALU): The ALU is a component within the CPU responsible for performing arithmetic calculations (addition, subtraction, multiplication, division) and logical operations (AND, OR, NOT) on data. The ALU is controlled by the control unit and processes data according to the instructions provided.
- Control Unit (CU): The control unit manages the flow of data between the CPU, memory, and input/output devices. It coordinates the execution of instructions, directs data movement, and ensures proper sequencing of operations.
- Input/Output (I/O): The Von Neumann architecture includes mechanisms for input and output operations, allowing the computer to interact with the external world. Input devices (e.g., keyboards, mice) provide data to the computer, and output devices (e.g., displays, printers) display the results of computations.
- Finite Instruction Set: The Von Neumann architecture operates based on a finite set of instructions that the CPU understands and can execute. These instructions define operations like loading data from memory, performing calculations, and transferring data between registers.
- Fetch-Decode-Execute Cycle: This cycle is at the heart of the Von Neumann architecture’s operation. The control unit fetches an instruction from memory, decodes it to determine the operation to perform, and then executes the operation. This cycle repeats for each instruction in the program.
The Harvard architecture
The Harvard architecture is a computer architecture with physically separate storage and signal pathways for instructions and data. It was developed independently of the Von Neumann architecture and is named after the Harvard Mark I relay-based computer, which was one of the earliest machines to use this design which stored instructions on punched tape (24 bits wide) and data in electro-mechanical counters.
In the Harvard architecture, the separation of data and instruction memory is a defining characteristic. Unlike the Von Neumann architecture, where both data and instructions are stored in the same memory space, the Harvard architecture uses separate memory spaces for instructions and data.
Some examples of Harvard architectures involve early computer systems where programming input could be in one media, for example, punch cards, and stored data could be in another media, for example, on tap. More modern computers may have modern CPU processes for both systems, but separate them in a hardware design.
The Harvard architecture can mitigate the Von Neumann bottleneck to some extent. In traditional architectures, fetching both instructions and data over a single memory bus can lead to contention and reduced performance.
Key Features of the Harvard Architecture
- Separate Instruction and Data Memory: In a Harvard architecture system, there are two memory units: one for storing instructions (program code) and another for storing data. This separation allows for simultaneous access to both instruction and data memory, which can improve the overall throughput of the system.
- Parallel Fetch and Execution: The separation of instruction and data memory enables parallelism in the fetch and execution of instructions. While one part of the processor is fetching an instruction, another part can simultaneously access or manipulate data. This parallelism can lead to faster program execution, especially in applications that involve frequent data processing.
- Faster Instruction Fetch: Because the instruction memory can be optimized solely for fetching instructions, the Harvard architecture can potentially achieve faster instruction fetch times compared to architectures where instructions and data share the same memory space. This optimization can lead to more efficient program execution.
- Potential for Code and Data Protection: The physical separation of instruction and data memory can offer a degree of code and data protection. It becomes harder for malicious code to manipulate or exploit data in memory, as they reside in different memory spaces.
- Embedded Systems and Specialized Applications: The Harvard architecture is often used in specialized computing systems, such as microcontrollers and digital signal processors (DSPs). These systems often require fast and efficient execution of specific tasks and can benefit from the architecture’s parallelism and optimized memory access.
- Complexity and Cost: Implementing a Harvard architecture can be more complex and expensive than a Von Neumann architecture, as it requires separate memory units and associated hardware. However, advancements in integrated circuit technology have mitigated some of these challenges over time.
Von Neumann vs Harvard Architecture: Key Differences
Memory Separation
- Von Neumann: Uses a single memory space for both instructions and data. Instructions and data are fetched from the same memory.
- Harvard: Utilizes separate memory spaces for instructions and data. Instructions and data have their own dedicated memory units.
Instruction and Data Buses
- Von Neumann: Shares a common bus for both instruction and data transfer, leading to potential bottlenecks.
- Harvard: Employs separate buses for instruction and data transfer, allowing parallel access and reducing bottlenecks.
Parallel Access
- Von Neumann: Cannot simultaneously fetch an instruction and access data due to the shared bus.
- Harvard: Permits simultaneous instruction fetch and data access, enhancing overall system efficiency.
Pipelining
- Von Neumann: Typically more challenging to implement pipelining due to potential instruction and data conflicts.
- Harvard: Easier to implement pipelining as separate memory spaces reduce conflicts and allow for better instruction processing parallelism.
Instruction Fetch
- Von Neumann: Fetches one instruction at a time from memory.
- Harvard: Can fetch multiple instructions simultaneously, enabling faster instruction processing.
Instruction and Data Caches
- Von Neumann: Often has a unified cache for instructions and data.
- Harvard: Has separate instruction and data caches, which can result in better cache performance and reduced contention.
Program Execution
- Von Neumann: Allows self-modifying code, where data can be treated as instructions, enabling flexible program execution.
- Harvard: Generally discourages self-modifying code due to the strict separation of instruction and data memory.
Complexity
- Von Neumann: Generally simpler to design and implement due to the shared memory and bus.
- Harvard: Can be more complex due to the need for separate memory spaces and buses.
Space Efficiency
- Von Neumann: Can be more space-efficient since instructions and data share the same memory.
- Harvard: May require more physical memory due to the separation of instruction and data memory.
Use Cases
- Von Neumann: Suited for general-purpose computing where flexibility and simplicity are important, such as in most modern computers.
- Harvard: Often used in embedded systems and specific applications where real-time processing and efficiency are critical, like microcontrollers and digital signal processors.
Von Neumann Vs. Harvard Architecture: Key Takeaways
| BASIS OF COMPARISON | VON NEUMANN ARCHITECTURE | HARVARD ARCHITECTURE |
| Description | The Von Neumann architecture is a theoretical design based on the stored-program computer concept. | The Harvard architecture is a modern computer architecture based on the Harvard Mark I relay-based computer model. |
| Memory System | Has only one bus that is used for both instructions fetches and data transfers. | Has separate memory space for instructions and data which physically separates signals and storage code and data memory. |
| Instruction Processing | The processing unit would require two clock cycles to complete an instruction. | The processing unit can complete an instruction in one cycle if appropriate pipelining plans have been set. |
| Use | Von Neumann architecture is usually used literally in all machines from desktop computers, notebooks, high performance computers to workstations. | Harvard architecture is a new concept used specifically in microcontrollers and digital signal processing (DSP). |
| Cost | Instructions and data use the same bus system therefore the design and development of control unit is simplified, hence the cost of production becomes minimum. | Complex kind of architecture because it employs two buses for instruction and data, a factor that makes development of the control unit comparatively more expensive. |