A Supervised Learning Algorithm (SLA) is a type of machine learning method in which a model is trained on labeled data — meaning the input data is paired with the correct output. The goal of the algorithm is to learn a mapping function from inputs to outputs so it can make accurate predictions on new, unseen data. This approach is called “supervised” because the process of training is guided by known outcomes, much like a teacher supervising a student.
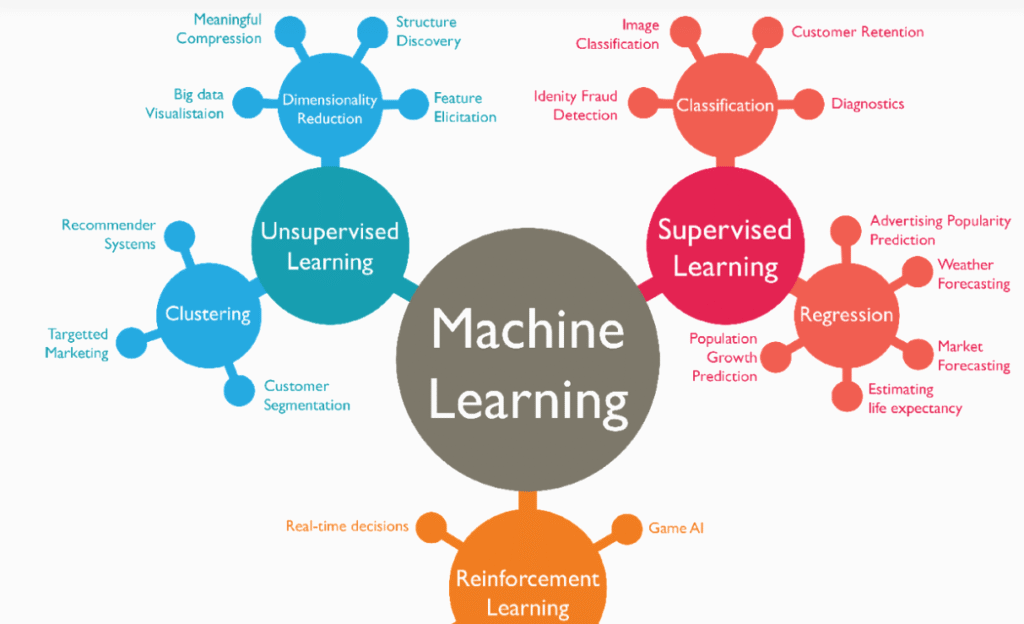
Supervised learning operates on two main types of tasks: regression and classification. Regression is used when the target variable is continuous, such as predicting prices, temperatures, or sales. Classification, on the other hand, deals with categorical outcomes, like determining whether an email is spam or not. Both rely on minimizing the difference between predicted and actual outcomes through iterative optimization.
The strength of SLAs lies in their ability to learn complex relationships from data when enough labeled examples are provided. By analyzing these examples, the algorithm can generalize patterns that help it perform well on similar future cases. However, their accuracy largely depends on the quality and quantity of training data — poor or biased datasets can lead to unreliable predictions.
Supervised learning algorithms come in various forms, ranging from simple models like Linear Regression and Decision Trees, to more advanced ones like Support Vector Machines, Random Forests, and Neural Networks. Each algorithm has unique strengths suited for specific types of problems — some are better for interpretability, while others excel in handling complex, nonlinear data.
Despite their effectiveness, supervised learning models face certain challenges. They require large amounts of labeled data, which can be time-consuming and expensive to produce. Additionally, overfitting can occur if a model learns too closely from the training data, performing poorly on new data. Techniques like regularization, cross-validation, and ensemble methods are often used to mitigate these issues.
Supervised Learning Algorithms
Linear Regression
Linear regression is one of the simplest supervised learning algorithms, used to predict continuous outcomes based on input features. It assumes a linear relationship between independent variables and the target variable.
This algorithm is widely used in forecasting and trend analysis, such as predicting sales, housing prices, or temperatures. Its simplicity and interpretability make it an excellent starting point for regression problems, though it struggles with nonlinear data.
Logistic Regression
Logistic regression is used for classification tasks where the output is categorical, such as yes/no or true/false. It applies the logistic function to estimate probabilities that an input belongs to a particular class.
Despite its name, logistic regression is a classification algorithm, not a regression one. It’s commonly used in spam detection, medical diagnosis, and credit scoring due to its ability to handle binary and multiclass classification efficiently.
Decision Trees
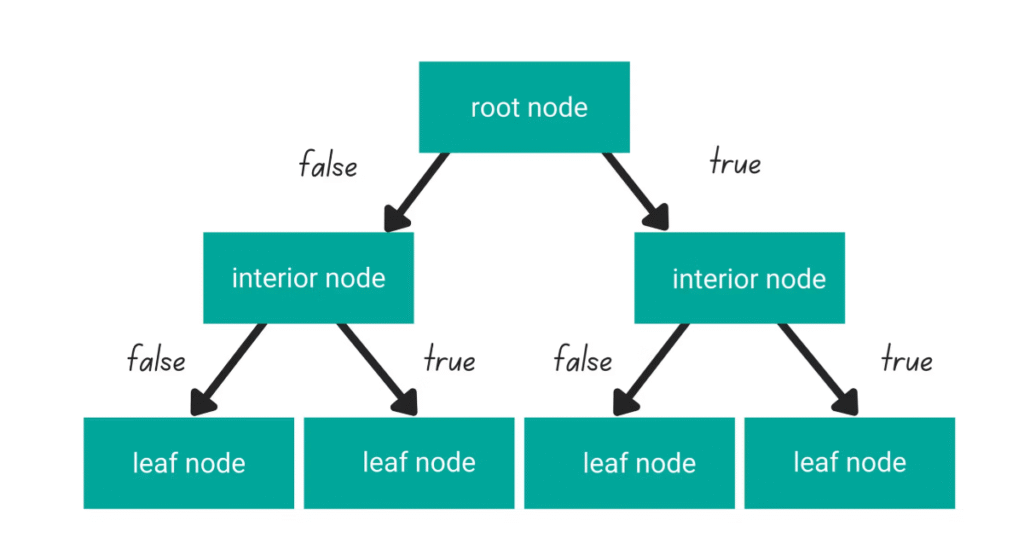
Decision trees split data into branches based on feature values, creating a model that resembles a flowchart. Each node represents a decision rule, and each leaf corresponds to a prediction outcome.
They are easy to understand and interpret but can overfit if not pruned properly. Decision trees are effective in both classification and regression problems, making them a popular choice for structured and categorical data.
Random Forest
Random forest is an ensemble method that combines multiple decision trees to improve accuracy and reduce overfitting. Each tree is trained on random subsets of data and features, and the final output is based on the average or majority vote of all trees.
This algorithm is known for its robustness and high performance in complex datasets. It’s widely used in finance, healthcare, and bioinformatics for tasks such as risk assessment, prediction, and anomaly detection.
Support Vector Machines (SVM)
Support Vector Machines are powerful algorithms that classify data by finding the optimal boundary, or hyperplane, that separates classes. They work especially well in high-dimensional spaces and can use kernel functions for non-linear data.
SVMs are unique in their ability to handle both linear and non-linear classification problems. They are often used in image recognition, text categorization, and bioinformatics where clear decision boundaries are crucial.
K-Nearest Neighbors (KNN)
KNN is a simple algorithm that classifies data based on the majority class among its nearest neighbors in the feature space. It does not build an explicit model but relies on data similarity for prediction.
This method is intuitive and effective for smaller datasets where patterns are easy to detect. However, KNN can be computationally expensive for large datasets and sensitive to irrelevant features or noisy data.
Naive Bayes
Naive Bayes is a probabilistic classifier based on Bayes’ Theorem, assuming independence between features. It calculates the probability that a given input belongs to each class and assigns the one with the highest likelihood.
Despite its simplicity and “naive” assumption, it performs surprisingly well for text classification, spam filtering, and sentiment analysis. It’s fast, efficient, and works well even with small amounts of training data.
Gradient Boosting
Gradient Boosting builds an ensemble of weak learners, usually decision trees, in a sequential manner where each tree corrects the errors of the previous one. It focuses on minimizing the loss function by optimizing residuals at every step.
This algorithm is highly effective for complex prediction problems and is used in advanced systems like XGBoost, LightGBM, and CatBoost. Gradient boosting is known for its accuracy, though it requires careful tuning to avoid overfitting and maintain performance.
AdaBoost (Adaptive Boosting)
AdaBoost is an ensemble learning method that combines multiple weak classifiers to form a strong model. It adjusts the weights of misclassified instances, forcing subsequent models to focus more on difficult examples.
This adaptive mechanism makes AdaBoost effective at reducing bias and variance in data. It’s widely used for both classification and regression problems, especially in face detection, fraud detection, and risk analysis. However, it can be sensitive to noisy data and outliers.
XGBoost (Extreme Gradient Boosting)
XGBoost is an optimized version of gradient boosting designed for speed and performance. It uses regularization techniques to control overfitting and efficiently handles missing data and large datasets.
XGBoost is known for its high accuracy and scalability, often used in machine learning competitions and real-world applications like financial modeling, click-through rate prediction, and healthcare analytics. It’s one of the most powerful algorithms in predictive modeling.
LightGBM (Light Gradient Boosting Machine)
LightGBM is another gradient boosting framework that focuses on fast training and low memory usage. It uses a histogram-based approach to split data, improving computation efficiency and scalability.
This algorithm is unique for handling large-scale and high-dimensional data effectively. It’s widely used in industries dealing with massive datasets, such as e-commerce, finance, and recommendation systems. Its speed and accuracy make it a favorite for time-sensitive projects.
CatBoost
CatBoost is a gradient boosting algorithm developed by Yandex, particularly well-suited for handling categorical data. It automatically processes non-numeric variables, reducing the need for extensive preprocessing.
What makes CatBoost unique is its ability to prevent overfitting while maintaining interpretability. It’s highly effective in applications like customer segmentation, demand forecasting, and natural language processing where categorical features dominate.
Elastic Net Regression
Elastic Net combines the strengths of Lasso and Ridge regression by using both L1 and L2 regularization. This helps in selecting important features while controlling overfitting in complex models.
The Elastic Net is ideal for datasets with many correlated variables. It’s widely applied in econometrics, genomics, and predictive analytics, offering a balance between model simplicity and predictive strength.
Ridge Regression
Ridge regression introduces an L2 penalty to the loss function to prevent overfitting and manage multicollinearity. It shrinks the coefficients of less important features toward zero without fully eliminating them.
This algorithm is especially useful for high-dimensional data and regression problems where predictors are highly correlated. Ridge regression enhances stability and generalization, making it a trusted tool in scientific and engineering modeling.
Lasso Regression
Lasso regression applies an L1 penalty to the coefficients, which can shrink some of them to zero entirely, effectively performing feature selection. It helps simplify models and enhance interpretability.
Lasso is valuable when dealing with large numbers of variables and limited data. It’s commonly used in bioinformatics, economics, and marketing analytics to identify the most relevant predictors while avoiding overfitting.
Quadratic Discriminant Analysis (QDA)
QDA is a classification algorithm that models each class separately using a quadratic decision boundary. Unlike Linear Discriminant Analysis (LDA), it allows each class to have its own covariance matrix, making it more flexible.
This algorithm is ideal for datasets where the relationship between classes is non-linear. It’s used in medical diagnosis, pattern recognition, and financial prediction, offering higher accuracy when the class distributions differ significantly.
Linear Discriminant Analysis (LDA)
Linear Discriminant Analysis is a classification algorithm that finds a linear combination of features that best separates two or more classes. It projects data into a lower-dimensional space while maximizing the distance between different classes.
LDA is particularly effective when classes have similar covariance structures. It’s often used in face recognition, marketing segmentation, and medical diagnosis, where dimensionality reduction and interpretability are both essential.
Bayesian Networks
Bayesian Networks use probabilistic graphical models to represent the relationships among variables. They apply Bayes’ theorem to predict the likelihood of outcomes based on prior knowledge and observed data.
These models are powerful for reasoning under uncertainty and handling missing information. They are commonly applied in risk analysis, healthcare decision-making, and predictive maintenance, offering insights into cause-and-effect relationships.
Perceptron Algorithm
The Perceptron is one of the earliest supervised learning algorithms, forming the foundation of modern neural networks. It classifies data by finding a linear boundary that separates different classes based on weighted inputs.
Despite its simplicity, it paved the way for deep learning models. The perceptron works best for linearly separable data and is used in applications like pattern recognition and binary classification tasks.
Multi-Layer Perceptron (MLP)
A Multi-Layer Perceptron is a more advanced version of the perceptron that includes multiple hidden layers of neurons. It uses nonlinear activation functions, allowing it to model complex relationships between input and output data.
MLPs are the basis of many modern artificial neural networks and are widely used in computer vision, speech recognition, and predictive analytics. Their flexibility makes them suitable for both regression and classification problems.
Relevance Vector Machine (RVM)
The Relevance Vector Machine is a probabilistic model similar in structure to the Support Vector Machine but provides sparse solutions with fewer support vectors. It incorporates Bayesian inference to determine the most relevant data points for prediction.
RVM offers probabilistic predictions and improved interpretability over traditional SVMs. It’s applied in regression, classification, and signal processing, where understanding uncertainty and reducing complexity are key advantages.